Kafka в проде: как встроенное сжатие спасло кластер, когда retention не успевал чистить диск
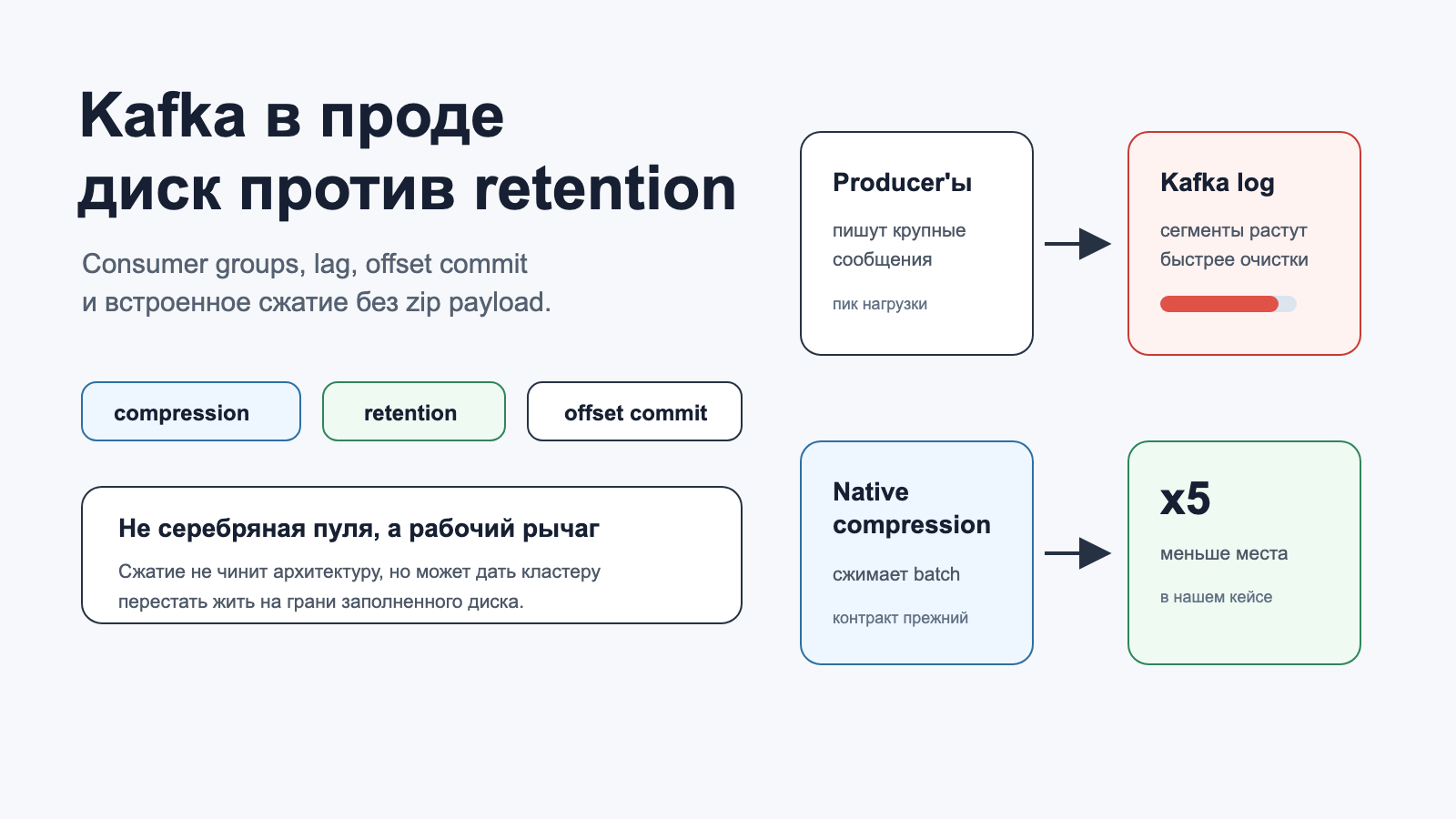
Привет, Хабр! Меня зовут Павел, я ведущий разработчик. В этой статье расскажу про Kafka, consumer groups, lag, offset commit и встроенное сжатие сообщений. Не в формате “что такое Kafka за 15 минут”, а через обычную продовую историю, где кластер начал есть диск быстрее, чем политики очистки успевали его освобождать. Снаружи проблема выглядела банально: Kafka живет, producer’ы пишут, consumer’ы читают, retention настроен. Внутри было веселее: в пиковую нагрузку место на брокерах улетало так бодро, будто у него был отдельный KPI на исчезновение. Retention вроде бы должен был чистить старые данные, но он не маг. Если входящий поток крупных сообщений быстрее, чем Kafka успевает освобождать сегменты, диск все равно закончится. А когда диск заканчивается у Kafka, настроение портится не только у Kafka. В итоге мы пришли к встроенному сжатию Kafka на producer’ах. Без ручного zip payload, без “давайте завернем JSON в архив и пусть каждый consumer теперь разбирается сам”. Просто включили compression на уровне Kafka-клиента. В нашем случае объем сообщений на хранении уменьшился примерно в 5 раз. Это не отменило необходимость следить за retention, lag и consumer groups, но дало кластеру перестать жить в режиме “еще один пик, и пишем посмертную”. Читать далее
Комментарии
Загрузка…